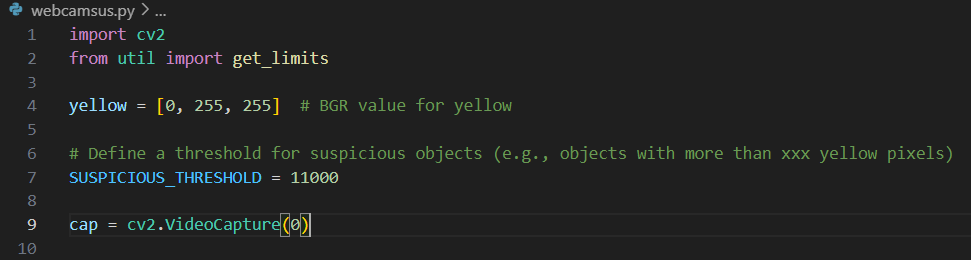
Method
Using OpenCV as the program for computer vision, it's few main usage is for object detection and video process. Using the functions available, I incorporated the code with colored-pixel detection and with a threshold limit.
The narrative intended was to create a data value scanner using computer vision that evaluates through the amount of dominant color pixels in an image with the “what if” scenario of selling your daily data of anything as commodity.